")
- Введение
- Что такое машинное обучение?
- Типы машинного обучения
- 1. Обучение под наблюдением
- 2. Обучение без учителя
- 3. Обучение с подкреплением
- Обучение под наблюдением
- Алгоритмы контролируемого обучения
- Работа с контролируемым обучением
- Приложения контролируемого обучения
- Обучение без учителя
- Примеры обучения без учителя
- Алгоритмы неконтролируемого обучения
- Работа с неконтролируемым обучением
- Приложения неконтролируемого обучения
- Обучение с подкреплением
- Алгоритмы обучения с подкреплением
- Работа с обучением с подкреплением
- Применение обучения с подкреплением
- Контролируемое или неконтролируемое обучение с подкреплением в ML
- Специализированные типы машинного обучения
- 1. Обучение под контролем
- Как это работает:
- Приложения:
- 2. Обучение под контролем
- Как это работает:
- Приложения:
- 3. Глубокое обучение
- Как это работает:
- Приложения:
- Текущие тенденции и будущие направления в машинном обучении
- Новые технологии и алгоритмы
- Этические соображения и проблемы
- Прогнозы для будущих разработок
Введение
Машинное обучение – это раздел искусственного интеллекта, который предполагает придание машинам большего сходства с людьми в их решениях и поведении. Это исследование позволяет машинам автоматически извлекать уроки из данных и разрабатывать свои программы, чтобы они могли работать лучше и делать прогнозы. Весь процесс выполняется без вмешательства человека, без явного программирования. Автоматизированный процесс обучения основан на опыте работы машины на протяжении всего процесса обучения.
Высококачественные данные передаются машинам для их обучения; различные алгоритмы помогают в построении моделей машинного обучения, и на основе обучения машины выполняют конкретную задачу. Выбор алгоритма зависит от типа имеющихся данных и задачи, которую необходимо автоматизировать.
Это подмножество искусственного интеллекта использует данные и алгоритмы для имитации поведения человека, и со временем машины совершенствуются, становясь более точными, анализируя данные и составляя классификации. Это можно сделать тремя способами – комбинируя алгоритмы и данные для прогнозирования структуры данных и их классификации, используя функцию ошибок для оценки точности и оптимизируя ее в соответствии с точками данных в модели.
В машинном обучении существует три типа обучения, и мы подробно изучим каждый из них в этом блоге.
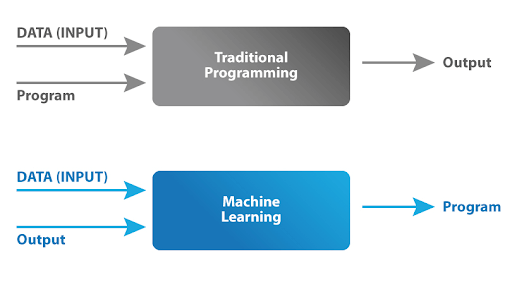
Что такое машинное обучение?
Машинное обучение – это раздел искусственного интеллекта (ИИ), который фокусируется на предоставлении компьютерам возможности учиться на данных и принимать решения на их основе. Чтобы понять суть машинного обучения, полезно подумать о том, как учатся люди.
На протяжении всей жизни мы постоянно собираем информацию, извлекаем уроки из своего опыта и принимаем решения на основе того, что узнали. Целью машинного обучения является имитация этого процесса для компьютеров, но вместо использования человеческого опыта оно использует данные.
Вот простой способ взглянуть на это:
- Ввод данных: Представьте, что вы вводите в компьютер большой объем данных. Эти данные могут быть любыми – числами, изображениями, текстом и т.д.
- Обучение: Затем компьютер использует алгоритмы (которые похожи на сложные математические формулы) для обработки этих данных. Эти алгоритмы предназначены для распознавания шаблонов, установления связей и вывода выводов из данных, во многом похожих на то, как ребенок учится распознавать шаблоны в своем окружении.
- Принятие решений или прогнозов: После обработки данных и извлечения из них уроков компьютер может затем принимать решения или прогнозы на основе новых данных, которые он получает. Это все равно что научить ребенка распознавать разные фрукты, показав ему несколько примеров, а затем попросить его идентифицировать фрукт, которого он раньше не видел.
Типы машинного обучения
Используя алгоритмы машинного обучения, мы можем решать различные бизнес-задачи, такие как классификация, регрессия, кластеризация, прогнозирование, ассоциация и многое другое. В зависимости от способа и методов обучения, в ML существует три типа обучения.
1. Обучение под наблюдением
- Метод обучения: обучение на основе помеченных данных. Это означает, что алгоритм обучается на данных, которые уже содержат ответы, часто называемые “основной правдой”.
- Использование: Идеально подходит для сценариев, в которых исторические данные предсказывают вероятные будущие события. Это похоже на обучение с учителем, который дает ответы.
- Приложения: Классификация (например, обнаружение спама), регрессия (например, прогноз цен на жилье).
- Плюсы: Высокоточные результаты для помеченных наборов данных.
- Минусы: Требует большого количества помеченных данных; неэффективно, если данные меняются со временем.
2. Обучение без учителя
- Метод обучения: Работает с немаркированными данными. Алгоритм пытается найти закономерности и взаимосвязи в данных без каких-либо указаний.
- Использование: Отлично подходит для поискового анализа, когда вы не знаете, что искать в данных.
- Приложения: Кластеризация (например, сегментация клиентов), ассоциация (например, анализ рыночной корзины).
- Плюсы: Может обрабатывать сложные, неструктурированные данные; хорош для обнаружения скрытых закономерностей в данных.
- Минусы: Менее точное, чем обучение под наблюдением; интерпретация результатов может быть сложной.
3. Обучение с подкреплением
- Метод обучения: Учится, взаимодействуя с окружающей средой. Он принимает решения, видит результаты и получает вознаграждения или штрафы.
- Использование: Лучше всего подходит для сценариев, в которых агент должен принять последовательность решений, которые со временем принесут наибольшую выгоду.
- Приложения: Игры (например, AlphaGo), робототехника, решения в режиме реального времени (например, автономные транспортные средства).
- Плюсы: Может решать сложные задачи, требующие принятия решений; постоянно адаптируется к новым сценариям.
- Минусы: Требует больших вычислительных мощностей; разработка системы вознаграждения может быть сложной.
Обучение под наблюдением
Контролируемое обучение считается наиболее используемым машинным обучением среди лидеров корпоративных информационных технологий в 2022 году. Оно получило название контролируемого, поскольку во время обучения машина находится под наблюдением.
Итак, мы передаем информацию алгоритму, чтобы помочь ему в обучении. Этот тип ML передает исторические входные и выходные данные в алгоритмы ML и обрабатывает их между каждой парой ввода / вывода, что позволяет алгоритму изменять модель для генерации выходных данных, соответствующих желаемому результату.
Выходные данные, предоставляемые машине, помечаются данными, а остальная информация используется в качестве входных функций. Обучение под наблюдением используется для различных бизнес-целей, таких как оптимизация запасов, прогнозирование продаж и обнаружение мошенничества.
Например, мы хотим знать взаимосвязь между неплатежами по кредитам и информацией о заемщике. Итак, мы предоставляем машинную информацию о 200 случаях неплатежей по своим кредитам и 200 других случаях, когда этого не произошло. Помеченные данные контролируют работу машины, чтобы найти информацию, которую мы ищем.
Распространенными примерами обучения под наблюдением являются:
- Определение того, являются ли банковские транзакции мошенничеством или нет
- Прогнозирование цен на недвижимость
- Выявление факторов риска заболеваний
- Прогнозирование выхода из строя механических частей промышленного оборудования
- Определение того, относятся ли соискатели кредита к категории низкого или высокого риска
Алгоритмы контролируемого обучения
Популярные алгоритмы контролируемого обучения включают:
- Линейная регрессия
- K Ближайших соседей
- Дерево решений
- Логистическая регрессия
- Машина опорных векторов
- Случайный лес
- Наивный Байес
Работа с контролируемым обучением
- Алгоритмы контролируемого обучения принимают помеченные входные данные и сопоставляют их с известными выходными данными, поэтому мы уже знаем целевое значение.
- Как следует из названия, эти типы методов ML требуют внешнего контроля для обучения систем машинного обучения. Им требуются рекомендации и дополнительная информация для получения желаемого результата.
Приложения контролируемого обучения
- Контролируемое обучение используется для решения задач регрессии и классификации.
- Оно также используется для прогнозирования погоды, анализа цен на акции и прогнозирования продаж.
Обучение без учителя
В отличие от обучения под наблюдением, для управления моделью которого требуется учитель или супервайзер, обучение без учителя обучается само по себе, распознает закономерности и извлекает взаимосвязи между данными без использования помеченных наборов обучающих данных. Оно ищет менее очевидные закономерности в данных и оперирует только входными переменными.
Кроме того, отсутствуют целевые переменные, которыми можно руководствоваться в процессе обучения. Он направлен на интерпретацию базовых шаблонов в данных для достижения большего мастерства в работе с базовыми данными. Обучение без учителя полезно, когда нам нужно выявить закономерности и использовать данные для принятия решений.
Обучение без учителя подразделяется на две категории
- Кластеризация – когда задача также включает в себя поиск различных групп в данных на основе определенных свойств.
- Оценка плотности – для консолидации распределения данных.
Цель выполнения этих операций – ознакомиться с шаблоном в данных. Проектирование и визуализацию также можно рассматривать как обучение без учителя, поскольку они оба пытаются дать представление о данных. Первый связан с уменьшением размерности данных, в то время как первый предполагает создание графиков на основе данных. Обучение без учителя обычно используется для создания прогнозирующих моделей.
Продолжая пример обучения под наблюдением, предположим, что мы не знаем клиентов, которые допустили дефолт по кредитам, а кто нет. Мы просто предоставляем машине информацию о заемщике, и она находит закономерности между заемщиками, чтобы сгруппировать их в разные кластеры.
Примеры обучения без учителя
Ниже приведены несколько распространенных примеров неконтролируемого обучения:
- Группировка запасов на основе показателей продаж или производства.
- Группирование клиентов на основе их покупательского поведения.
- Указывая на ассоциации в данных клиента, например, клиент, заинтересованный в определенном типе одежды, может искать определенный тип сумки или обуви.
Алгоритмы неконтролируемого обучения
В зависимости от типа задачи, которую вы хотите решить, вы выбираете правильный алгоритм. Несколько примеров алгоритмов обучения без учителя::
- Иерархическая кластеризация
- DBSCAN
- K Означает кластеризацию
- Гауссова смесь
- Анализ основных компонентов
Работа с неконтролируемым обучением
- Этот тип машинного обучения выявляет закономерности и понимает тенденцию изменения данных для поиска выходных данных. Модель помечает данные в соответствии с особенностями входных данных.
- Процесс обучения не требует какого-либо контроля для построения моделей, поскольку он обучается самостоятельно и прогнозирует результат.
Приложения неконтролируемого обучения
- Неконтролируемое обучение используется при сегментации клиентов. Мы можем классифицировать клиентов и группировать их на основе антипатий, симпатий, поведения и интересов.
- Оно также используется при анализе оттока.
- Мы можем использовать неконтролируемое обучение для решения задач кластеризации и ассоциации.
Обучение с подкреплением
Обучение с подкреплением – это тип машинного обучения, наиболее близкий к тому, как учатся люди. Здесь агенты или алгоритм учатся, взаимодействуя с окружающей средой и получая вознаграждение, будь то положительное или отрицательное. Распространенными алгоритмами являются глубокие состязательные сети, временные различия и Q-learning.
Платформы машинного обучения не обладают навыками обучения с подкреплением, поскольку они требуют более высоких вычислительных мощностей, чем те, что есть в организациях. Этот тип ML применим в полностью моделируемых областях, которые либо стационарны, либо содержат огромное количество релевантных данных. Поскольку этот алгоритм машинного обучения требует меньше управления, чем обучение под наблюдением, считается, что работать с немаркированными наборами данных проще.
Снова рассматривая пример с клиентом с возвратом кредита, мы можем использовать алгоритм обучения с подкреплением для поиска информации о клиенте. Если алгоритм классифицирует клиента как клиента с высоким уровнем риска и невыполнением обязательств, алгоритм получит положительное вознаграждение. Однако, если значение по умолчанию отсутствует, алгоритм получает отрицательное вознаграждение. Таким образом, оба случая помогают машине лучше понять проблему и окружающую среду.
Некоторые практические приложения для машинного обучения с подкреплением все еще появляются. Его примеры включают:
- Динамическое управление светофорами для уменьшения пробок.
- Обучение автомобилей автоматической парковке и вождению.
- Обучение роботов изучению политик с использованием необработанных видеоизображений в качестве входных данных, чтобы они могли воспроизводить действия, которые они видят.
Алгоритмы обучения с подкреплением
Важными алгоритмами обучения с подкреплением являются следующие:
- Q-learning
- Monte Carlo
- Sarsa
- Сеть Deep Q
Работа с обучением с подкреплением
- Подкрепление относится к числу типов систем машинного обучения, которые используют методы проб и ошибок для получения желаемых результатов. Как только задача выполнена, агент получает награду.
- Например, мы обучаем собаку ловить мяч. Как только она научится и поймает мяч, мы вознаграждаем ее лакомствами.
- Задачи с подкреплением основаны на вознаграждении, поэтому за каждое выполненное задание агент получает вознаграждение. Однако, если задание выполнено неправильно, будет добавлено какое-либо наказание.
- Эти методы не требуют какого-либо внешнего контроля для обучения моделей.
Применение обучения с подкреплением
Машинное обучение с подкреплением распространено в игровой индустрии, где оно используется для создания игр. Оно также используется при обучении роботов выполнять человеческие задачи.
Контролируемое или неконтролируемое обучение с подкреплением в ML
Вот табличное сравнение трех типов машинного обучения – контролируемого, неконтролируемого и обучения с подкреплением:
| Критерии | Обучение под наблюдением | Обучение без учителя | Обучение с подкреплением |
| Тип данных | Помеченные данные | Немаркированные данные | Нет предопределенных данных (извлекается из среды) |
| Метод обучения | Учится на примерах с известными результатами | Исследует данные для поиска шаблонов или структур | Учится методом проб и ошибок для достижения определенной цели |
| Основная цель | Прогнозирование результатов или классификация данных | Обнаружение скрытых закономерностей или группирование | Максимизация вознаграждения в данной среде |
| Приложения | Классификация (например, фильтрация спама по электронной почте), регрессия (например, прогноз цен на жилье) | Кластеризация (например, сегментация клиентов), уменьшение размерности (например, выделение признаков) | Игры (например, шахматы), автономные системы (например, самоуправляемые автомобили) |
| Плюсы | Высокая точность благодаря помеченным данным, прямая обратная связь | Нет необходимости в маркированных данных, подходит для поискового анализа данных | Высокая адаптивность к динамичным средам, эффективность при принятии сложных решений |
| Минусы | Требуется большое количество помеченных данных, что менее эффективно при изменении данных с течением времени | Результаты могут быть неоднозначными, более сложными для интерпретации | Разработка эффективной системы вознаграждения может быть сложной с точки зрения вычислительных затрат |
| Пример | Распознавание цифр, написанных от руки | Группирование клиентов на основе покупательского поведения | Робот , обучающийся ориентироваться в лабиринте |
Специализированные типы машинного обучения
Специализированные типы машинного обучения, такие как обучение с частичным контролем, обучение с самоконтролем и глубокое обучение, представляют собой более тонкие подходы или достижения в этой области.
1. Обучение под контролем
Это гибридный подход, который представляет собой нечто среднее между обучением под присмотром и без присмотра. Обучение под наблюдением использует комбинацию небольшого количества помеченных данных и большого количества немаркированных данных во время обучения.
Как это работает:
Небольшой набор помеченных данных направляет процесс обучения, а затем модель применяет это понимание к большему набору немаркированных данных. Это может привести к повышению эффективности и точности обучения, особенно когда помеченных данных мало или их получение дорого.
Приложения:
Обучение под наблюдением полезно в сценариях, где получение помеченных данных является дорогостоящим или трудоемким, например, при анализе медицинских изображений, где для маркировки требуются экспертные знания.
2. Обучение под контролем
Это подмножество неконтролируемого обучения, при котором система генерирует свои собственные метки на основе данных. Это похоже на студента, который создает практические вопросы из учебника, а затем разрабатывает ответы.
Как это работает:
Алгоритм учится предсказывать часть своих входных данных на основе других частей своих входных данных. Например, он может научиться предсказывать следующее слово в предложении. Сама задача прогнозирования создает “метки”, необходимые для обучения.
Приложения:
Самостоятельное обучение показало большие перспективы в задачах обработки естественного языка и компьютерного зрения, таких как генерация текста или понимание содержания изображений и видео без надписей с человеческими комментариями.
3. Глубокое обучение
Глубокое обучение – это подмножество машинного обучения, которое включает в себя нейронные сети со многими уровнями (отсюда термин “глубокий”). Эти сети способны обучаться на основе огромных объемов данных.
Как это работает:
Модели глубокого обучения автоматически и итеративно извлекают высокоуровневые функции из данных. Это отличается от традиционного машинного обучения, которое требует извлечения функций вручную.
Приложения:
Глубокое обучение успешно применяется в различных областях, включая распознавание речи, распознавание изображений, обработку естественного языка и даже при создании художественных образов. Это технология, лежащая в основе многих передовых систем искусственного интеллекта, таких как ассистенты с голосовым управлением и самоуправляемые автомобили.
Текущие тенденции и будущие направления в машинном обучении
Область машинного обучения (ML) быстро развивается, и новые тенденции и технологии определяют ее будущее. Давайте рассмотрим эти тенденции, а также этические соображения и потенциальные будущие разработки в ML.
Новые технологии и алгоритмы
- Автоматизированное машинное обучение (AutoML): Эта технология направлена на автоматизацию сквозного процесса применения машинного обучения к реальным проблемам. AutoML может выбирать оптимальные модели, настраивать параметры и даже предварительно обрабатывать данные, делая ML доступным для неспециалистов.
- Объяснимый ИИ (XAI): По мере усложнения моделей ML, особенно глубокого обучения, растет потребность в объяснимости. XAI фокусируется на том, чтобы сделать результаты этих моделей интерпретируемыми и прозрачными, что крайне важно для приложений в таких областях, как здравоохранение и финансы.
- Федеративное обучение: Это метод обучения моделей ML на нескольких децентрализованных устройствах или серверах, хранящих локальные выборки данных, без обмена ими. Это повышает конфиденциальность и безопасность, снижая риски централизации данных.
- Квантовое машинное обучение: Объединение ML с квантовыми вычислениями может революционизировать вычислительные возможности в области обработки данных и сложности моделей, потенциально решая проблемы, которые в настоящее время являются неразрешимыми.
Этические соображения и проблемы
- Предвзятость и справедливость: модели ML могут непреднамеренно сохранять и усиливать искажения, присутствующие в их обучающих данных. Обеспечение справедливости и устранение искажений в алгоритмах является серьезной этической проблемой.
- Конфиденциальность: Поскольку ML в значительной степени зависит от данных, проблемы, связанные с конфиденциальностью данных, имеют первостепенное значение. Для решения этих проблем появляются такие методы, как федеративное обучение и дифференцированная конфиденциальность.
- Прозрачность и подотчетность: Растет спрос на прозрачные модели ML, в которых решения могут быть объяснены и обоснованы, особенно в областях с высокими ставками, таких как здравоохранение и уголовное правосудие.
- Регулирование и контроль: По мере того, как ML становится все более влиятельным в обществе, растет потребность в соответствующих нормативных рамках. Это включает контроль над вредоносным использованием ИИ, таким как глубокие подделки или автономное оружие.
Прогнозы для будущих разработок
- Искусственный интеллект и ML как утилита: Подобно электричеству, ML может стать повседневной утилитой, органично интегрированной в повседневную жизнь и доступной каждому, а не только крупным корпорациям.
- Прогресс в обработке естественного языка (NLP): Ожидается дальнейшее совершенствование NLP, ведущее к более сложным и детализированным взаимодействиям человека и компьютера.
- Персонализированное и прогностическое здравоохранение: ML, вероятно, позволит использовать высоко персонализированные методы лечения и прогностические модели для профилактики заболеваний и ведения пациентов.
- Устойчивый ИИ: Учитывая воздействие обучения больших моделей ML на окружающую среду, будет сделан толчок к созданию более энергоэффективных систем ИИ.
- Междисциплинарные приложения: Мы увидим растущее сочетание ML с другими областями, такими как геномика, астрономия и материаловедение, что приведет к прорывам, которые ранее были невозможны.
 в машинном обучении")





: Архитектура, Модели, Полное руководство")
 в сельском хозяйстве: Роль, Применение, примеры")